www.anandtech.com
Keep cherrypicking and quoting partial numbers, multiple reviewers are testing and overall power consumption of the Mac unit (I wonder if all are setting the new macOS High Power mode settings, not the default btw) vs the laptop they test again is the strong suit of the MBP’s…
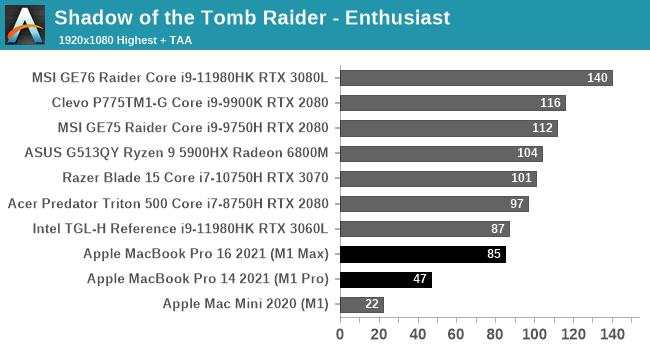
Even from your link: “Apple never really intended these chips to be used for gaming, and to be honest,
the energy efficiency of these chips is something that is unmatched by any notebook touting an RTX 3060 or RTX 3080.”
I would also give some time for all vendors to update software (especially Adobe) to take as a stage of the new ARM codes. Interesting you keep bringing integrated GPU (M1) vs systems with dedicated GPU’s. We will see at the end of the day the best performance : battery life ratio too I guess
")
. Anyways, this is not the attitude that Intel needs to win these kind of contracts back and do not expect Apple to lose money or sleep over this.
The big challenge will be the Mac Pro where their own designs allow for multiple dedicated GPU’s… I wonder if they will still allow them or how they plan to scale this design (they did not start from mobile to tablet to 13’’ MBP to larger MBP’s for no reason).